UNISTAT - příklad 4
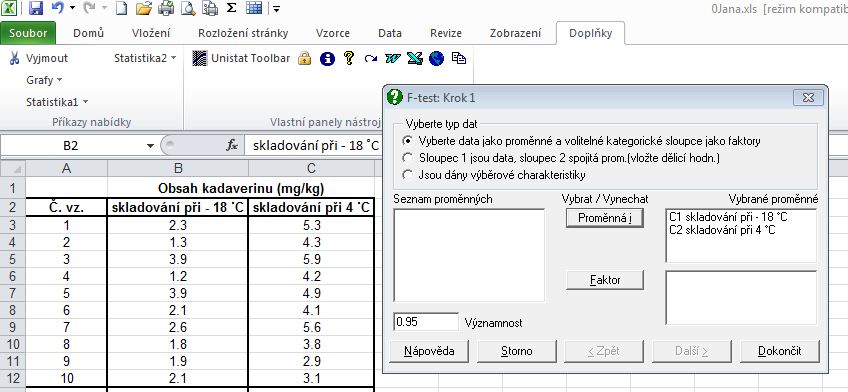
1. Zadání hodnot do tabulky MS Excel, označení bloku buněk B2 až C12; protože porovnáváme 2 výběry dat pocházející ze 2 různých skupin vzorků, jedná se o nepárovou situaci (nepárový t-test), kdy musíme nejprve otestovat rozdíl rozptylů obou souborů dat pomocí F-testu. Pro výpočet F-testu zvolit menu Statistika1 - Parametrické testy - F-test. V dialogu vybrat příslušné proměnné (skladování -18 °C, skladování 4 °C):
2. Zobrazení výsledku F-testu:
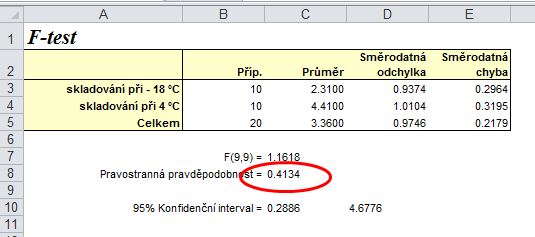
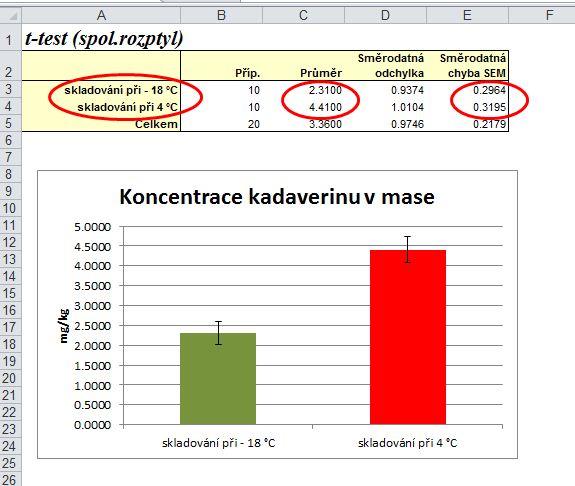
Výsledek F-testu: protože testujeme nulovou hypotézu H0:s12=s22(shodu rozptylů), která předpokládá tzv. oboustranný test, musíme výslednou pravostrannou pravděpodobnost násobit dvěma, tzn. že výsledkem je pravděpodobnost p = 0,8268 (pravděpodobnost chyby α pro tento test). Protože tato p > 0,05, znamená to, že rozdíl mezi testovanými rozptyly je statisticky nevýznamný na hladině významnosti 0,05 (platí tedy nulová hypotéza H0:s12=s22), tj. rozptyly obou souborů se neliší.
3. Výpočet nepárového t-testu (pro společný rozptyl): označit sloupce B, C a zvolit menu Statistika1 - Parametrické testy - t-test (spol. rozptyl). V dialogu vybrat příslušné proměnné (skladování -18 °C, skladování 4 °C):
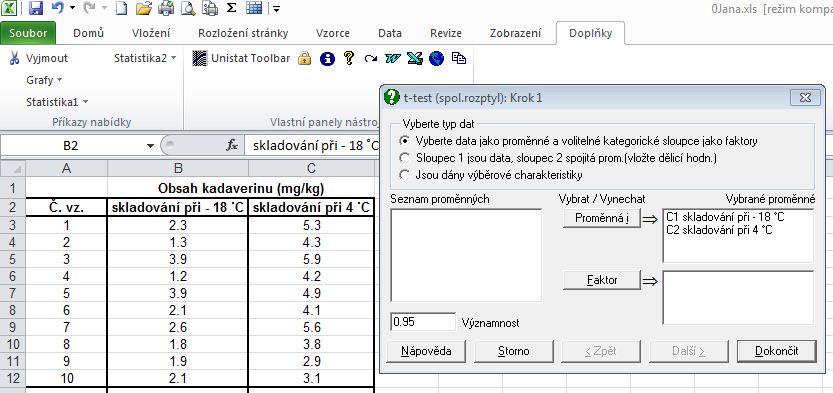
4. Zobrazení výsledku t-testu:
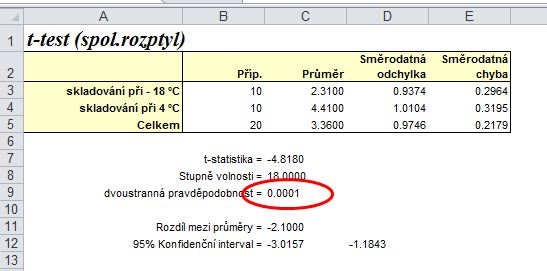
Výsledek t-testu: protože testujeme nulovou hypotézu H0:m12=m22 (shodu středních hodnot), výsledkem je dvoustranná pravděpodobnost p = 0,0001. Protože je tato pravděpodobnost p < 0,01, znamená to, že rozdíl mezi testovanými středními hodnotami je statisticky vysoce významný (zamítáme tedy nulovou hypotézu o shodě středních hodnot).
5. Závěr: Protože je rozdíl mezi průměry obou souborů statisticky vysoce významný (p < 0,01), ovlivňuje odlišná teplota skladování obsah kadaverinu ve vepřovém mase: u masa skladovaného při 4°C je obsah kadaverinu vysoce významně vyšší než u masa skladovaného při -18 °C.
6. Pro lepší přehlednost dosažených výsledků a jejich interpretaci je vhodné použít i grafické znázornění - graf je možno vytvořit pomocí obvyklých nástrojů Excelu z označených buněk v tabulce výsledků t-testu (hodnoty SEM jsou použity pro tzv. chybové úsečky). Tvorba chybových úseček: po označení sloupců v grafu vyvolat menu: Nástroje grafu - Rozložení - Chybové úsečky - Další možnosti chybových úseček - Vlastní (tady zadat do kladné i záporné chybové hodnoty 2 buňky s vypočtenými hodnotami SEM).