Při sledování kvalitativních statistických znaků a následné analýze kategoriálních dat vycházíme z pravděpodobnosti výskytu daného znaku v populaci a z četností jedinců odpovídajících jednotlivým kategoriím (kvalitativním třídám) sledovaného nominálního znaku ve výběrových souborech. Získané četnosti (kategoriální data) zachycujeme pomocí jedno-, dvou- nebo vícerozměrných tabulek četností (případně relativních četností, procent). Každý rozměr (dimenze) tabulky odpovídá klasifikaci do kategorií podle určitého kvalitativního znaku.
Při zkoumání četností kategoriálních dat stojíme před podobnými úkoly jako v případě numerických dat u kvantitativních znaků. Můžeme porovnávat četnosti výskytu sledovaného kvalitativního znaku ve výběrovém souboru, se statistickou pravděpodobností výskytu tohoto znaku, která je teoreticky známá pro celou populaci. Můžeme také porovnávat četnosti výskytu sledovaného znaku mezi dvěma, případně i více výběrovými soubory nebo zjišťovat sílu závislosti jednotlivých kvalitativních znaků mezi sebou.
Základním statistickým postupem, který je nejčastěji využíván při analýze kategoriálních dat je c2-test (Chí kvadrát test) pro testování rozdílů četností (jak mezi soubory, tak i pro zjišťování závislosti kvalitativních znaků).
Při výpočtech spojených s analýzou kategoriálních dat pomocí c2-testu používáme s následujícím označením četností:
ne - empirická (pozorovaná) četnost výskytu znaku (platí pro výběrový soubor)
no - očekávaná (teoretická) četnost výskytu znaku (platí pro populaci)
![]() Poměr empirické četnosti výskytu znaku ve výběrovém souboru k
celkovému počtu jedinců ve výběru představuje relativní četnost znaku (empirickou
pravděpodobnost výskytu daného znaku - pe):
Poměr empirické četnosti výskytu znaku ve výběrovém souboru k
celkovému počtu jedinců ve výběru představuje relativní četnost znaku (empirickou
pravděpodobnost výskytu daného znaku - pe):
Při nekonečném zvětšování
rozsahu výběrového souboru n dostaneme v limitě tzv.
statistickou (teoretickou) pravděpodobnost výskytu znaku - po (očekávanou
pravděpodobnost, předpokládanou pro celý základní soubor). Pro nekonečně velký
počet jedinců v populaci (N =
¥)
nelze statistickou pravděpodobnost prakticky vypočítat, můžeme ji pouze
odhadovat na základě empirické pravděpodobnosti. Čím větší je počet jedinců ve
výběrovém souboru, na kterém provádíme sledování, tím více se hodnota empirické
pravděpodobnosti (pe)
blíží k skutečné hodnotě teoretické pravděpodobnosti (po):![]()
Testování rozdílů četností se (obecně) provádí c2-testem. Rozdíl mezi empirickými (pozorovanými) a teoretickými (očekávanými) četnostmi zachycuje testovací statistika, která má tvar:
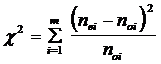
kde
m = počet kvalitativních tříd (kategorií) představujících varianty kvalitativního znaku
nei = empirická četnost (data z výběrového souboru)
noi = očekávaná četnost (teoretická, známá pro základní soubor)
Protože platí, že ne= pe . n a no= po . n , lze použít i výraz :
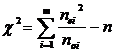
Je-li vypočtená statistika c2 = 0, znamená to, že pozorované a teoretické četnosti jsou přesně stejné. Čím větší je hodnota c2, tím větší je nesouhlas mezi empirickou (ne) a teoretickou (no) četností v jednotlivých třídách.
Pro posouzení statistické významnosti rozdílu srovnávaných četností porovnáme vypočtený c2 s tabulkovou kritickou hodnotou c21-a (n). Jako kritické hodnoty pro c2–test slouží 1-a kvantily c2 - rozdělení při n = m-1 stupních volnosti (viz Tabulky: Kritické hodnoty rozdělení c2).
Pokud vypočtená statistika (testovací kritérium) c2 přesáhne tabulkovou kritickou hodnotu c21-a (n), prohlásíme, že pozorované četnosti nei nesouhlasí statisticky významně s teoreticky očekávanými četnostmi noi na hladině významnosti a.